

Add a New Datastore from SFTP/ AWS S3
You can create a new datastore from SFTP or AWS S3. You can configure to flush the existing data from the datastore before loading new data.
Follow these steps to create a new datastore from SFTP/ AWS S3:
- Navigate to Data management > Data ingestions > Datastores list screen, and click Add new datastore.
- Select From SFTP / AWS S3 and click Proceed. The Datastore creation screen appears.
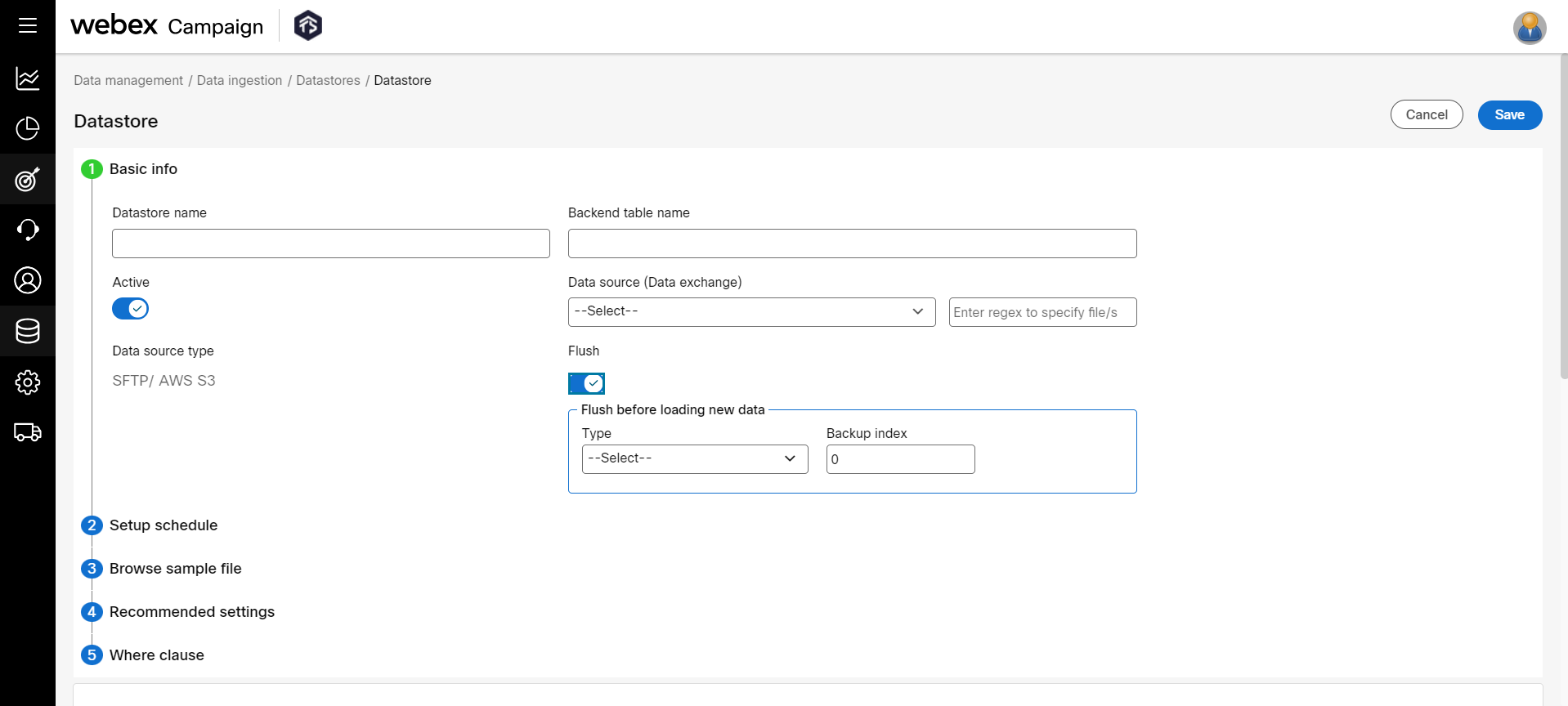
- In the Basic Information accordion, enter details for the following fields:
-
Datastore name: Enter a name to identify the datastore.
-
Backend table name: By default, the datastore name you enter will be displayed here. We recommend you proceed with the name that is displayed. In case you wish to have a different name for a backend datastore, then enter a name.
-
Data source (Data exchange): Select the SFTP location from where you want to import the data. You can enter the specific path of the source input file along with the pattern on its own or in conjunction with the SFTP selection. The location can be requested from Operations/your Customer Success Executive.
These formats can also be built as per the requirement. Following are some of the sample formats:
◘ ClientProfile&DD&&MM&&YYYY&&WORD&.csv.
◘ Client_Profile&YYYY&-&MM&-&DD&&WORD&.csv
◘ IMI_CM_EDR&YYYY&-&MM&-&DD&&WORD.txt
◘ &YYYY&-&MM&-&DD&/IMI_003&YYYY&&MM&&DD&_001.txt -
Active: Set the status to ‘ON’ to make the datastore active.
-
Flush : Set to ‘ON’, to flush the data before loading. Select the Flush type from the drop-down such as Hourly, Daily, Weekly, or Monthly. Enter the Backup index. This option is used to back up the data before deleting it from the system. For example, if you enter the backup index value as 2, then the system will back up the last 2 data imports. The archived data can only be accessed by L2/L3 only.
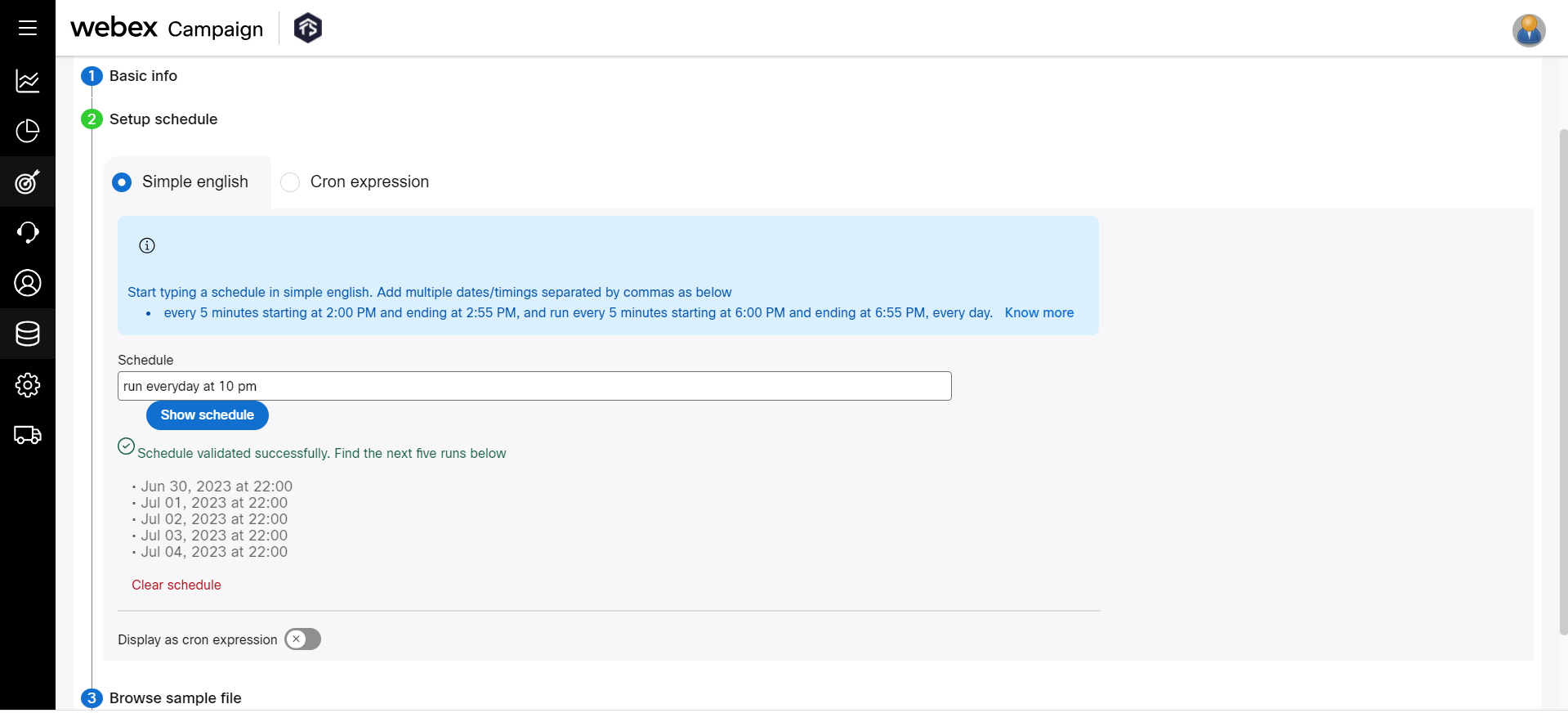
-
In the Setup schedule accordion, configure how frequently the data must be imported. Enter the schedule in simple English and click on Show schedule. The schedule is translated into a cron expression and displays the next 5 runs. Click Display as cron expression to view the schedule in Cron expression.
If the displayed schedule does not match your expected schedule then click on the Cron expression tab and enter the schedule in the Cron expression. Click here to know more about Cron Expressions.
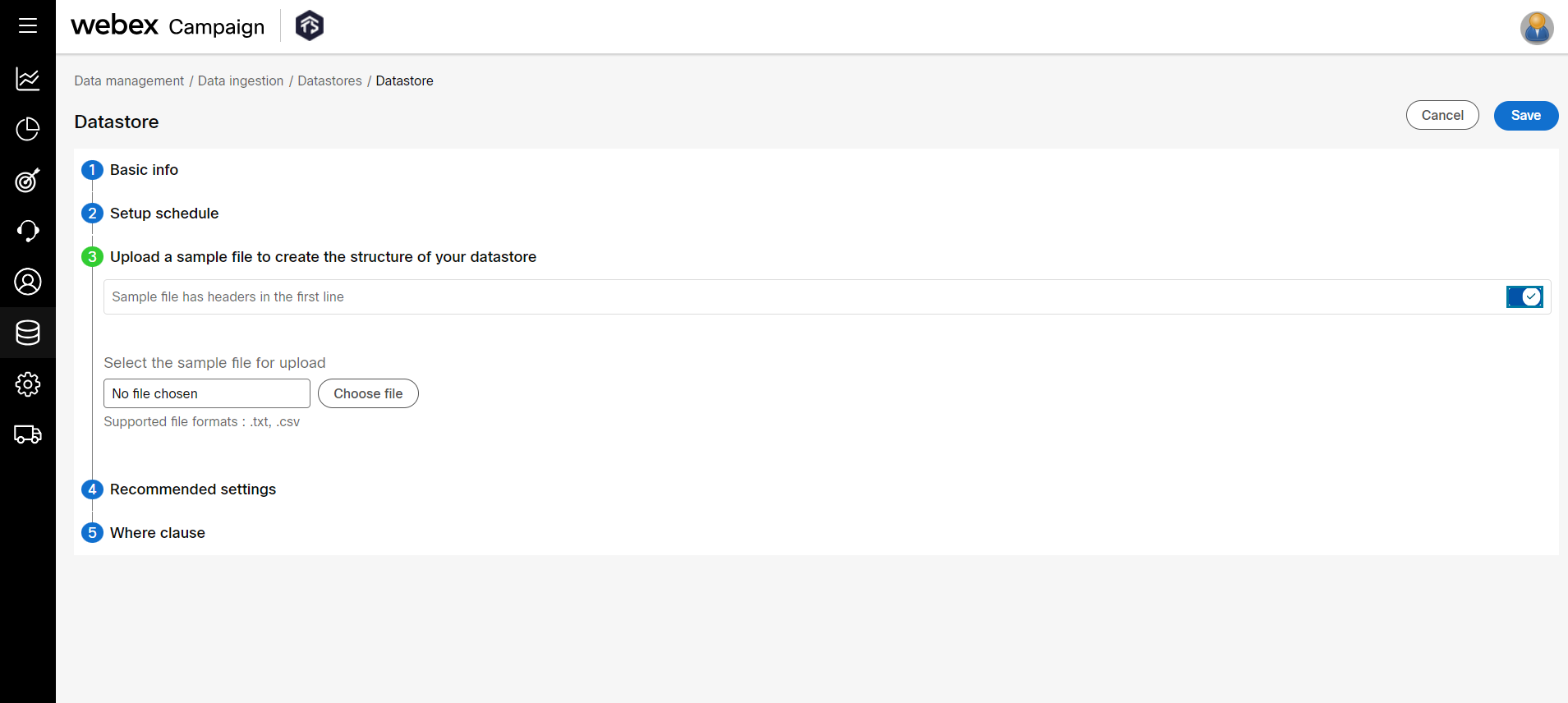
- In the Browse sample file accordion, enter details for the following fields:
- First line header: Set the status to ’ON’ if the file to be uploaded has its first line as the header.
- Select file for upload: Click Choose file and select the file. The supported file formats are .txt and .csv.
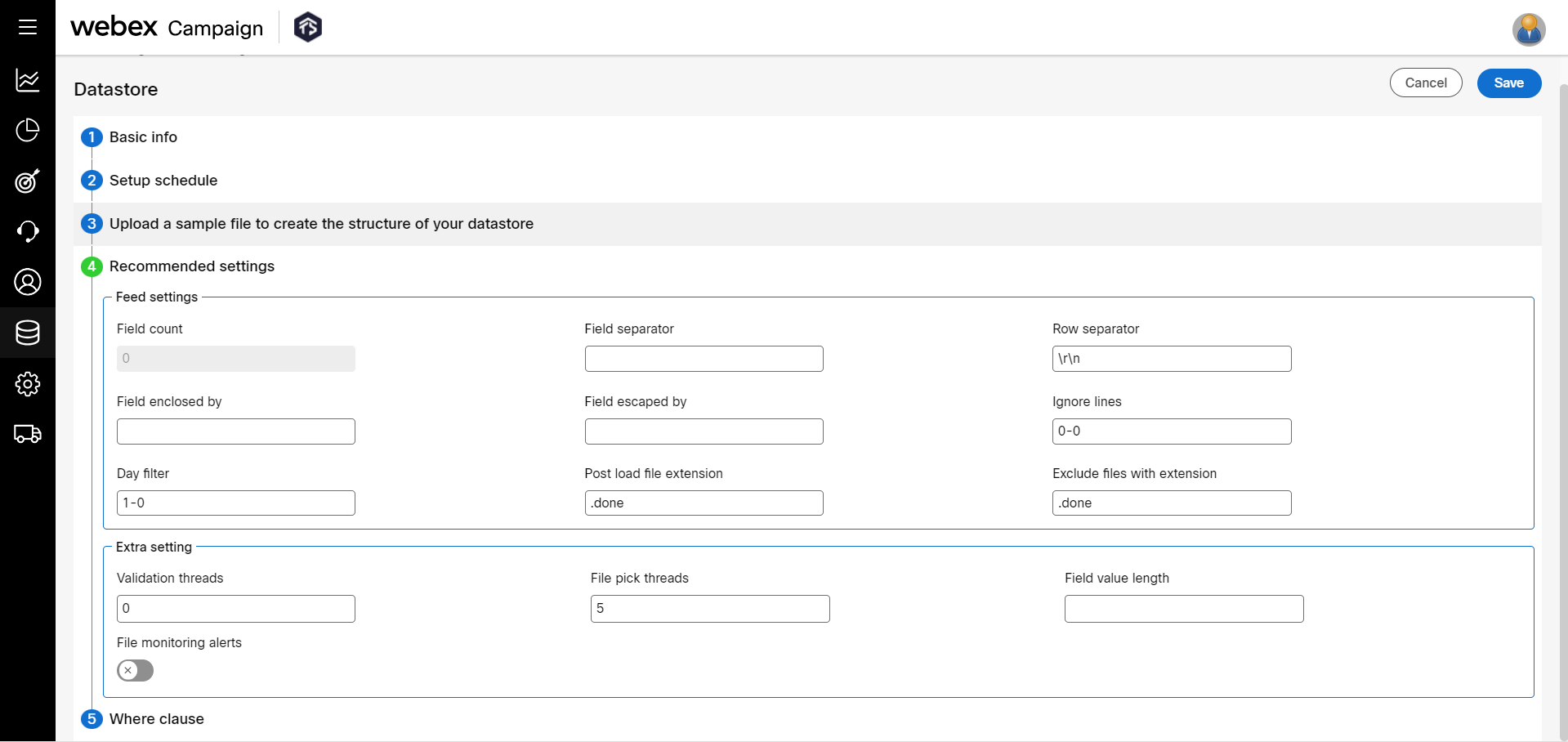
- (Optional) In the Recommended settings accordion, fields are populated automatically based on the selected input file. You can proceed with the recommended settings or change the settings as required.
- Field count: This field is updated automatically when the file is uploaded. It displays the number of fields that exist in the input file.
- Field separator: This field is updated automatically when the file is uploaded. It specifies the field separator to parse the input file.
- Row separator: This field is updated automatically when the file is uploaded. It displays the row separator for the input file. The default option is \r\n. Enter the row separator as identified in the input file if it is not updated by the system from the sample input file.
- Field enclosed by: To include a text field that is separated by a key. For example, if the input file has a field as sample1, sample2, "sample3", or 'sample4'. To include a field that is enclosed in " ", enter ". It indicates a field that is enclosed in " " must be included while loading the data.
- Field escaped by: To exclude a text field that is separated by a key. For example, if the input file has a field as sample1, sample2, "sample3", or 'sample4'. To exclude a field that is enclosed in ' ', enter '. It indicates that a field that is enclosed in ' ' must be excluded while loading the data.
- Ignore lines: Enter the line numbers separated by ‘-’ to be ignored while loading the data into the datastore. For example, if the log file has 500 records. if you configure ignore lines as 2-300, the top 2 lines and bottom 300 lines are ignored. If you enter 10-0, then only the top 10 lines are ignored. If you enter 0-10, only the bottom 10 lines are ignored.
- Day filter: If your source folder has many files and you want the system to pick up only the previous 5 days' files excluding the last 2 days. Enter the day filter separated by ‘-’. For example, if today's date is 15th June, if you enter 5-1, it indicates that the system has to pick up files of the previous 5 days and ignores the last 1 day from the current date. That means it will pick up files from 10th June to 14th June and ignores the 15th June files.
- Post load file extension: Enter a suffix that is added to the file name after loading the data into the datastore. For example, .comp or .done. The processed files will be renamed with the extension as specified.
- Exclude files with extension: Enter a list of file name suffixes separated by a comma to exclude from loading. For example, if your source folder contains file names with an extension as .done, then you have to enter .done. The files with the _.done _extension will not be picked up for data loading.
EXTRA SETTINGS
- Validation threads: Enter the number of threads used to validate the data while loading.
- File pick threads: Enter the number of files that can be picked up simultaneously for data loading. The default value is 5.
- Field value length: Enter the length of the field.
- File monitoring alerts: Set to ‘ON’, to enable the file monitoring alerts.
- (Optional) Enter Where clause details. Configure this option to load the data that satisfies the condition. If this option is not configured, the entire data will get loaded.
Expressions: Select a column and operator from the respective drop-downs, enter the value to be satisfied, and the operator between select clauses (for more than one clause) to build a where clause. Click + Add new to add more conditions. The data that satisfy the where clause will be loaded into the data store.
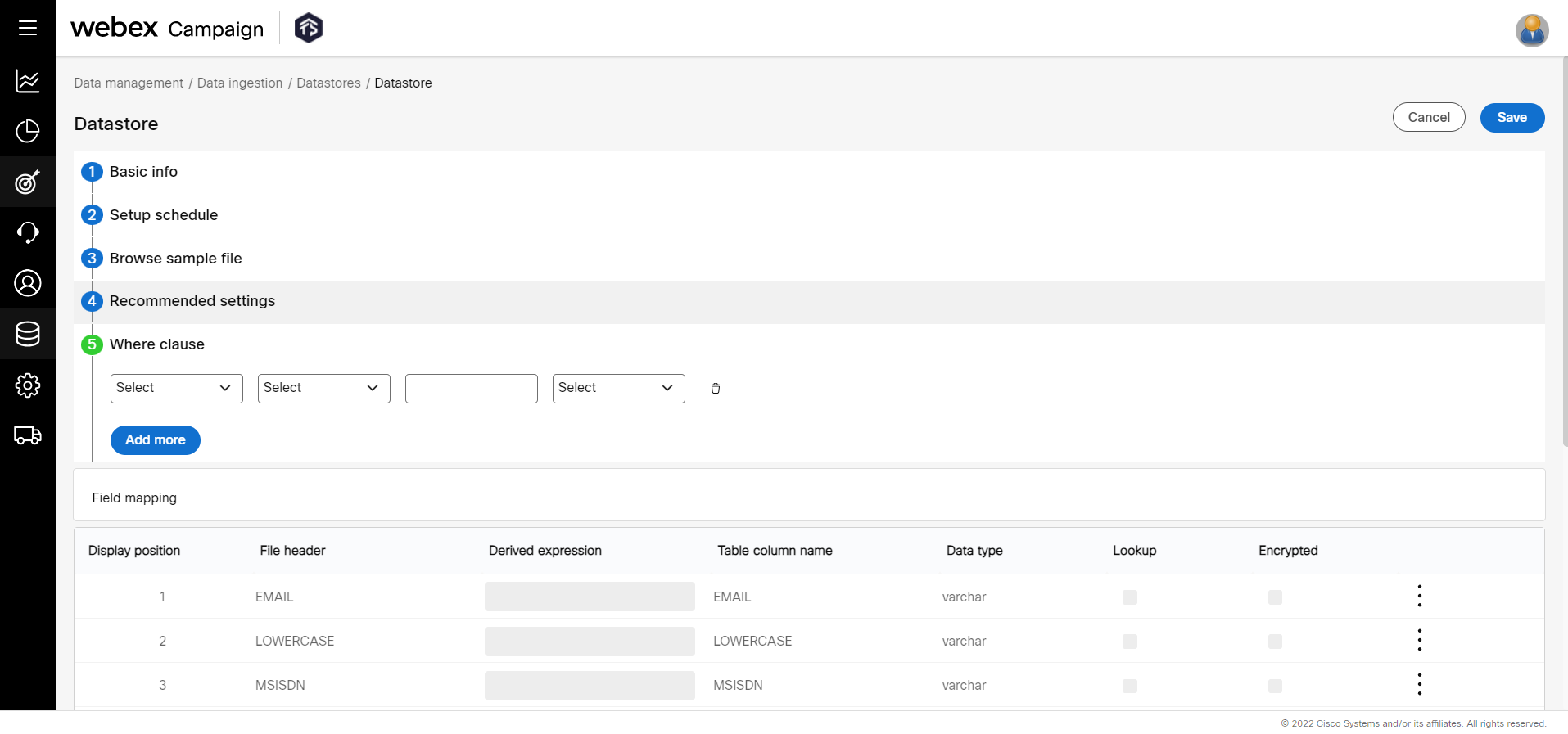
- (Optional) The field mapping view represents the fields of the data store. You can view all the columns in a single view. To Insert a header, edit, or delete a header, click on the respective actions.

- Click Save.
After creating the datastore you might have to add a new column to the datastore. Instead of deleting the datastore, you can insert a new column using the Insert New icon. To know how to add a header in a Datastore, click here.
You can View the Datastore Load Report for the respective datastore to check if the data has been loaded successfully.
Updated over 1 year ago